ChatGPT and Other LLMs: Should we Celebrate or be Afraid of These Technologies?
Ravi Pardesi
Strategic Business Director
At the Society for Scholarly Publishing’s annual meeting hosted in June 2023, we presented a panel discussion at our breakout session titled ChatGPT and other LLMs – should we celebrate or be afraid of these technologies?
I was joined by Abhi Arun (TNQTech’s CEO) and Neelanjan Sinha (TNQTech’s Product Specialist), and we delved into the world of artificial intelligence, machine learning, and large language models, and how they all fit together for the publishing industry.
AI-Assisted Poetry
In the spirit of exploring AI and what it can do, we asked Google Bard to write a poem that we could present at the event. We think the limerick suggested would have made Shakespeare (the original Bard) proud!
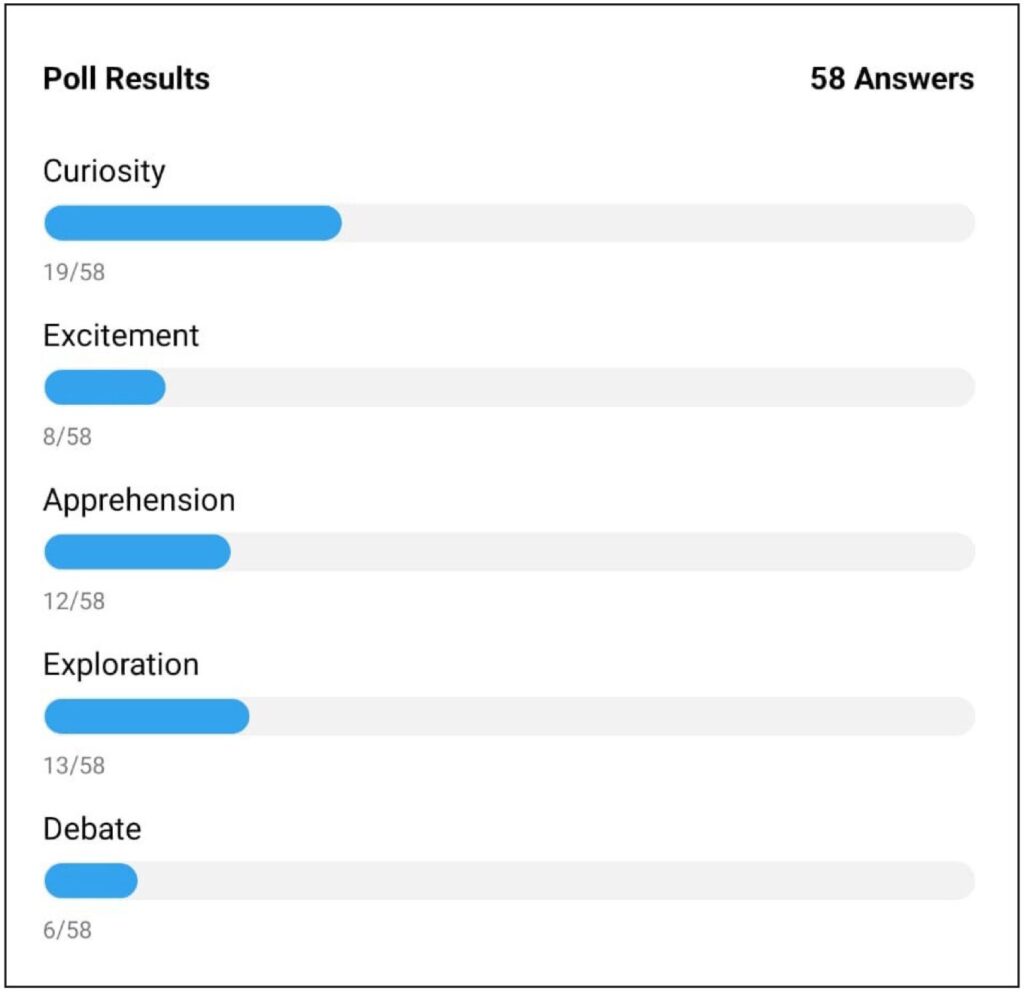
We then asked the audience to take a quick poll and tell us where they were on their emotional journey with ChatGPT. Curiosity emerged as the lead emotion, followed by exploration and apprehension.
At TNQTech, we went through all of the emotions ourselves when we first started talking about LLMs at the beginning of the year. Questions raced through our minds. Some were easy to answer, and some complex ones need more contemplation.
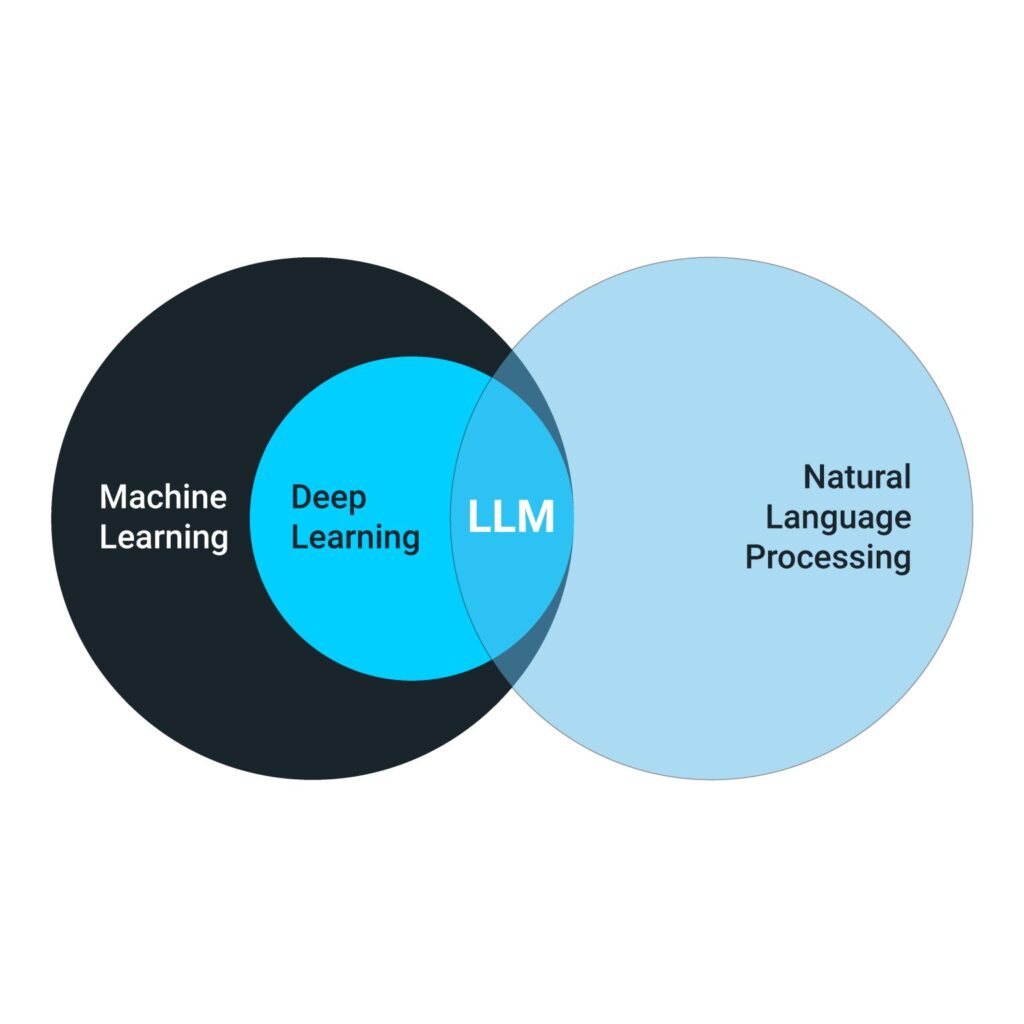
What is an LLM and How is it Different from AI and ML?
LLMs aren’t new, they have been around for a while. With the release of Open AI’s ChatGPT to the public in November last year, its human-like conversational capabilities have shot it to global fame.
AI itself is a rather broad field that aims to automate human tasks and mimic human intelligence. ML makes it possible for machines to learn using large amounts of data usually for a specific outcome or task. And large language models sit at the intersection between ML and natural language processing (NLP). The two most important keywords to understanding LLMs are “large” (trained on enormous datasets), and “language” (referring to the model’s ability to understand human language).
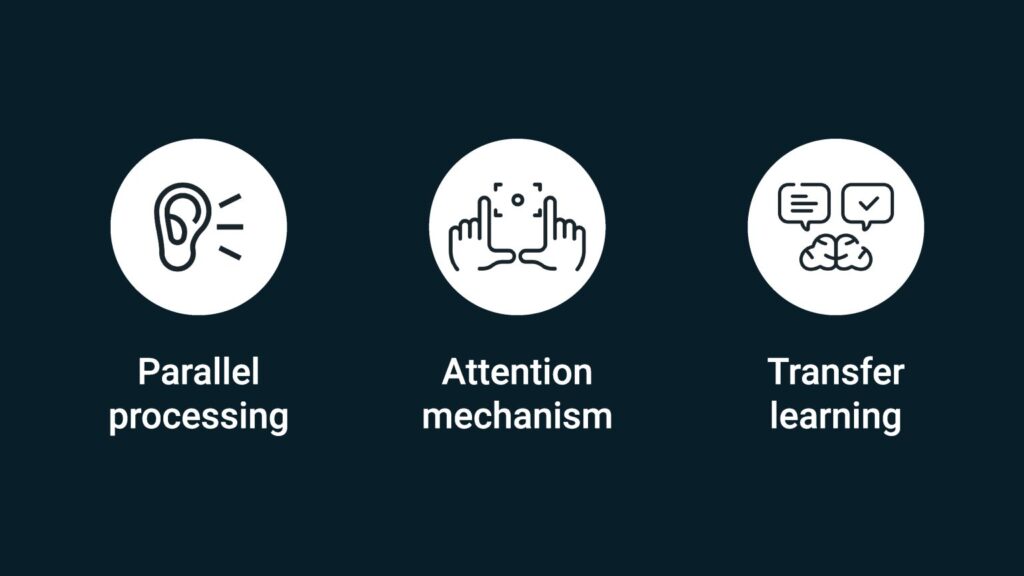
Attention is All you Need
We explored the technicalities of how ChatGPT works, digging deeper into parallel processing, attention mechanisms, and transfer learning. “The attention mechanism is the most foundational capability for large language models. It enables the model to understand context and semantics more deeply than the earlier models, making its responses far more nuanced and relevant. While parallel processing accelerates training and transfer learning improves adaptability, it’s the depth of understanding enabled by the attention mechanism that drives its efficacy,” explained Neelanjan.
ChatGPT and Research
“There are tremendous opportunities to use LLMs like ChatGPT within research itself,” said Abhi. “One of the biggest challenges we have heard is framing the right questions for research. This is where mentors add great value, but aren’t always available, especially for young researchers. ChatGPT can supplement their role and researchers can have conversations with it, just like they would their mentor. LLMs can help design experiments by suggesting relevant variables, methodologies and techniques. They can also help with statistical analysis of complex data.”
LLMs and STM Publishing
Across the 4 stages of the STM content value chain, LLMs like ChatGPT can provide significant support. In the creation stage, authors are using these tools to help with idea generation and mainly language editing (especially researchers from ESL countries).
In the moderation stage, LLMs could revolutionise the peer-review process. They can help generate summaries, extract key findings, and possibly expose gaps in results. We don’t think it will be too long before they are able to assist in the peer review process.
During production which includes structuring, copy editing, and typesetting, LLMs could expedite the integration of AI/ML technologies into the workflow, particularly around language and editing capabilities. But customer service and author support are areas where it can truly shine!
Lastly, in the distribution stage (print circulation, web hosting), LLMs could possibly assist with generating accessible versions of content, or story-like research summaries for wider public consumption. This bit is still being explored and there’s not a lot being done here just yet.
In summary, LLMs will have the most impact in the way research is conducted, and content is created and moderated.
We went into detail about the challenges around using LLMs in STM publishing, and ethicsand legality dominated owing to their propensityto hallucinate and the complications with authorship attribution. The big question around quality and unsupervised learning looms among other concerns.
Is ChatGPT Going to Take Away our Jobs?
Abhi says, “the short answer is – we don’t know. But history tells us that a technology this big will definitely change jobs and force us to evolve. My key takeaways are to not ignore this technology, don’t assume this will replace everything, make sure you are exploring this and its implications yourself, and do not rely on one-sided opinions.
The most important one however, is that the STM publishing industry must come together to overcome the threats that this technology presents.”
The team at our booth
Exploring LLMs at TNQTech
Our product teams have been using Google’s BERT for many of our AI/ML-driven projects. In order to extend the discipline at TNQTech, we are also exploring how LLM models can be leveraged in our operations and products for innovation and automation, while bearing in mind all challenges and concerns surrounding its use. More on this later.